The focus of this release is largely back-end improvements to Tigris, the online workflow authoring tool which is part of LearnSphere. We have also added several new Tigris workflow components, many in response to feedback we have received at workshops and conferences.
- Support for arrays in component options.
- New and updated workflow components.
- RISE
- OLI-to-RISE
- LFA Search
- Student Progress Classification
- Performance Difference Analysis
- Curriculum Pacing
- Multi-selection Converter
- Tetrad Simulation
- Wheel-spinning Detector
- Tetrad Graph Editor
- Tetrad Regression
- DataShop now includes support for non-instructional steps.
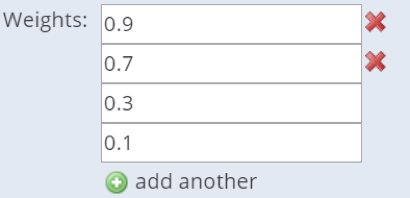
Tigris now supports array types for simple data types (double, integer, string), FileInputHeaders, and enumerated types (drop-down lists). The user can define default values for each value added, as well as the minimum and maximum number of allowed values. Array types are especially useful in cases where an unknown number of arguments is desirable. In this example, a variable 'weights' is defined as an array of xs:double values, with at least two required values.
Source code for all Tigris components can be found in our GitHub repository.
This R component helps to conduct RISE analyses as described in the paper The RISE Framework: Using Learning Analytics to Automatically Identify Open Educational Resources for Continuous Improvement..
For OLI datasets in DataShop, this component will generate an output file suitable for use in the RISE component. The output columns are skill name, average high-stakes error rate and average low-stakes error rate.
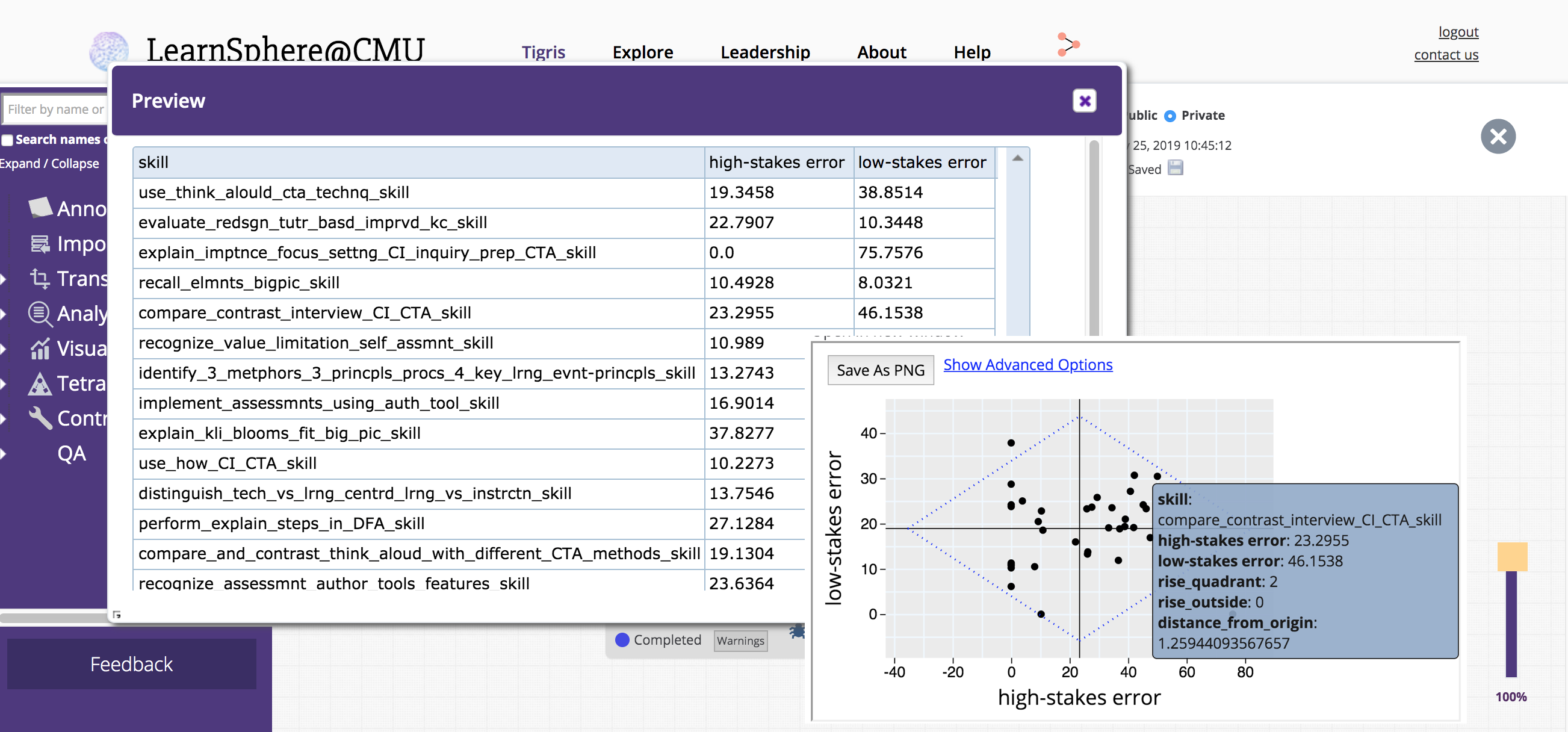
Learning Factors Analysis (LFA) performs a heuristic search to generate models of the input data. AFM (Additive Factors Model) is used to compute the metric (AIC or BIC) by which the models are compared for best fit.
This component, developed as part of the PL2 project, classifies a student's progress based on their EdTech usage, accuracy information and specified goal.
This component calculates performance differences for an individual course. The target use case is calculating gendered differences (or other factors) in final grade for a target course (e.g., intro physics), especially relative to grades in other courses taken by students in the target course. For reference: Koester, Grom, & McKay (2016) and Matz et al. (2017).
Curriculum Pacing is a way to visualize student learning trajectories through curriculum units and sections. This visualization is suitable to quickly explore end-to-end curriculum data and see patterns of student learning. More information can be found in this paper.
Given a DataShop transaction export, this component converts a multi-selection row into multiple rows of single steps and sets the Outcome values accordingly. Using a multi-selection item mapping file, an output transaction export is generated with each row labeled with the appropriate Event Type.
This component supports the Tetrad Simulation functionality that can be used to generate data from an instantiated model. This component allows Tigris to support the Tetrad functionality mentioned in this tutorial by Richard Scheines.
This component implements the algorithm given in Joe Beck's paper to detect if a student is wheel-spinning. The required input format is a DataShop student-step export.
The editor was extended to allow users to create graphs from scratch, generating named nodes and links in the options panel. The created graph is available for download.
A third output was added that includes an r2 value (a measure of how closely the data fits the regression line) and the sum of squared estimate of errors (SSE).
The dataset import procedure will now process a new column called Event Type in the tab-delimited transaction data file, if present. The allowed values for this column are: assess, instruct and assess_instruct. The assess event type is considered to be a non-instructional step; the other event types cause the learning opportunity count to be incremented by 1. Using non-instructional steps, you can grant partial credit to multi-selection questions. For example, in the following question the correct answer is A and B. When a student gives an answer of B and C, they should receive partial credit for selecting B.
